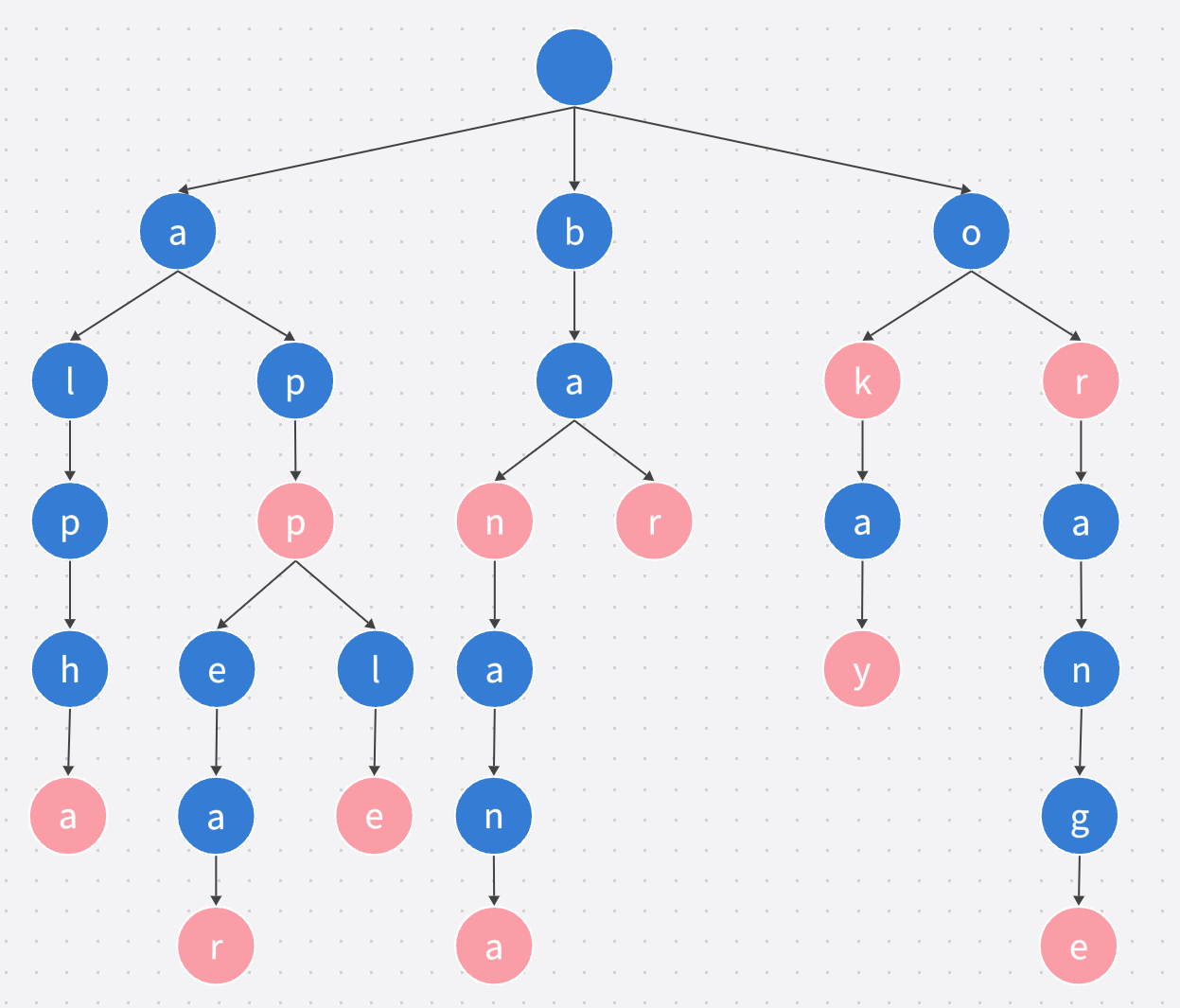
// 插入单词 word voidinsert(TrieNode* root, const string &word) { auto p = root; for(char c : word) // 逐个字符遍历 { int idx = c - 'a'; if(!p->children[idx]) // 如果这个字符节点还没有,创建节点 p->children[idx] = newTrieNode(); p = p->children[idx]; } p->isEnd = true; }
// 查询单词 word boolsearch(TrieNode* root, const string &word) { auto p = root; for(char c : word) { int idx = c - 'a'; if(!p->children[idx]) // 不存在这个字符 returnfalse; p = p->children[idx]; } return p->isEnd; }
// 查询是否存在以 prefix 为前缀的单词 boolstartsWith(TrieNode* root, const string &prefix){ auto p = tree; for(char c : prefix) { int idx = c - 'a'; if(!p->children[idx]) returnfalse; p = p->children[idx]; } returntrue; }

 微信
微信 支付宝
支付宝