记录 LeetCode 第 295 场周赛
本次周赛惨遭滑铁卢,仅仅写出第一题。前一天睡的太晚了,比赛的时候浑浑噩噩。第二题由于 double 强转 int 的精度问题,一直 WA,第三题又没有什么思路,第四题压根没看 (可惜第四题直接 Dijkstra 就可以 AC) 。
战局详情
| 排名 | 用户名 | 得分 | 完成时间 | 题目1(3) | 题目2(4) | 题目3(5) | 题目4(6) |
|---|---|---|---|---|---|---|---|
| 3944 / 6640 | Juruoer | 3 | 0:08:13 |
题目及解答
重排字符形成目标字符串
给你两个下标从 0 开始的字符串 s 和 target 。你可以从 s 取出一些字符并将其重排,得到若干新的字符串。
从 s 中取出字符并重新排列,返回可以形成 target 的 最大 副本数。
提示:
1 <= s.length <= 1001 <= target.length <= 10s和target由小写英文字母组成
示例一:
输入:s = “ilovecodingonleetcode”, target = “code”
输出:2
解释:
对于 “code” 的第 1 个副本,选取下标为 4 、5 、6 和 7 的字符。
对于 “code” 的第 2 个副本,选取下标为 17 、18 、19 和 20 的字符。
形成的字符串分别是 “ecod” 和 “code” ,都可以重排为 “code” 。
可以形成最多 2 个 “code” 的副本,所以返回 2 。
示例二:
输入:s = “abcba”, target = “abc”
输出:1
解释:
选取下标为 0 、1 和 2 的字符,可以形成 “abc” 的 1 个副本。
可以形成最多 1 个 “abc” 的副本,所以返回 1 。
注意,尽管下标 3 和 4 分别有额外的 ‘a’ 和 ‘b’ ,但不能重用下标 2 处的 ‘c’ ,所以无法形成 “abc” 的第 2 个副本。
示例三:
输入:s = “abbaccaddaeea”, target = “aaaaa”
输出:1
解释:
选取下标为 0 、3 、6 、9 和 12 的字符,可以形成 “aaaaa” 的 1 个副本。
可以形成最多 1 个 “aaaaa” 的副本,所以返回 1 。
解决方案:
计算 s 中每个字符的个数分别为 target 中每个字符的个数的多少倍,取最小倍数即为答案。
代码:
1 | class Solution |
时间复杂度为:,空间复杂度为:,m 和 n 分别为 s 和 target 的长度。
价格减免
句子 是由若干个单词组成的字符串,单词之间用单个空格分隔,其中每个单词可以包含数字、小写字母、和美元符号 '$' 。如果单词的形式为美元符号后跟着一个非负实数,那么这个单词就表示一个价格。
- 例如
"$100"、"$23"和"$6.75"表示价格,而"100"、"$"和"2$3"不是。
注意:本题输入中的价格均为整数。
给你一个字符串 sentence 和一个整数 discount 。对于每个表示价格的单词,都在价格的基础上减免 discount% ,并 更新 该单词到句子中。所有更新后的价格应该表示为一个 恰好保留小数点后两位 的数字。
返回表示修改后句子的字符串。
提示:
1 <= sentence.length <= 1e5sentence由小写英文字母、数字、' '和'$'组成sentence不含前导和尾随空格sentence的所有单词都用单个空格分隔- 所有价格都是 正 整数且不含前导零
- 所有价格 最多 为
10位数字 0 <= discount <= 100
示例一:
输入:sentence = “there are $1 $2 and 5$ candies in the shop”, discount = 50
输出:“there are $0.50 $1.00 and 5$ candies in the shop”
解释:
表示价格的单词是 “$1” 和 “$2” 。
- “$1” 减免 50% 为 “$0.50” ,所以 “$1” 替换为 “$0.50” 。
- “$2” 减免 50% 为 “$1” ,所以 “$1” 替换为 “$1.00” 。
示例二:
输入:sentence = “1 2 $3 4 $5 $6 7 8$ $9 $10$”, discount = 100
输出:“1 2 $0.00 4 $0.00 $0.00 7 8$ $0.00 $10$”
解释:
任何价格减免 100% 都会得到 0 。
表示价格的单词分别是 “$3”、“$5”、“$6” 和 “$9”。
每个单词都替换为 “$0.00”。
解决方案:
字符串模拟题,遍历字符串 sentence (也可以使用正则表达式),对于所有的价格计算出新的价格,构造新的字符串即可。
需要注意的是,此题要求保留两位小数,但若使用 float 类型或 double 类型强转成 int 类型会有精度错误,当然也可以不强转,而使用字符流 ostringstream 来格式化地将浮点型 保留指定小数位 并转为 ostringstream 型,再获取相应 string 型:
1 | //对于浮点型价格 price 保留两位小数转为字符流 |
也可以不使用浮点型,由于本题 discount 属于 0 到 100,故对于价格 price,price * (100 - discount) 即为打折后的价格的 100 倍,其最后两位数即为小数点后的值,且没有精度问题。
代码:
1 | class Solution |
时间复杂度:,空间复杂度:,n 为 sentence 的长度。
使数组按非递减顺序排列
给你一个下标从 0 开始的整数数组 nums 。在一步操作中,移除所有满足 nums[i - 1] > nums[i] 的 nums[i] ,其中 0 < i < nums.length 。
重复执行步骤,直到 nums 变为 非递减 数组,返回所需执行的操作数。
提示:
1 <= nums.length <= 1e51 <= nums[i] <= 1e9
示例一:
输入:nums = [5,3,4,4,7,3,6,11,8,5,11]
输出:3
解释:执行下述几个步骤:
- 步骤 1 :[5,3,4,4,7,3,6,11,8,5,11] 变为 [5,4,4,7,6,11,11]
- 步骤 2 :[5,4,4,7,6,11,11] 变为 [5,4,7,11,11]
- 步骤 3 :[5,4,7,11,11] 变为 [5,7,11,11]
[5,7,11,11] 是一个非递减数组,因此,返回 3 。
示例二:
输入:nums = [4,5,7,7,13]
输出:0
解释:nums 已经是一个非递减数组,因此,返回 0 。
解决方案:
若直接模拟,则时间复杂度为 显然 TLE。
可以使用 单调栈 + 动态规划 计算。
以下的 x 被 y 删除的意思是,经过一系列删除操作后 y 为 x 的前一个元素,且 y > x。
nums[i]若被删除,则一定是被nums[i]左边的某个值删除,可以证明,nums[i]若被删除,则其被删除所需的步数可以等价于被其左边第一个大于nums[i]的值(设为nums[j])删除所需的步数。以
[20,1,9,1,2,3]为例。时刻一
20删掉1,9删掉1;
时刻二20删掉9,9删掉2;
时刻三20接替了9的任务,来删除数字3。
虽然说数字3是被20删除的,但是由于20立马接替了9,我们可以等价转换成3是被9删除的,也就是它左边离它最近且比它大的那个数。这一等价转换不会影响数字被删除的时刻。
可以使用单调递减栈来计算每个元素左边第一个大于其的元素。
设删除 nums[i] 所需的步数为 dp[i] (若 nums[i] 不需要删除,则 dp[i] 等于 0),且假设 nums[i] 被 nums[j] 删除(或根据上述所说的等价于被nums[j]删除),则 nums[j + 1] 到 nums[i - 1] 均已被删除,则:
dp[i] = max(dp[j + 1], dp[j + 2], ... , dp[i - 1]) + 1。
单调递减栈出栈时刚好会将 nums[i] 左边小于其的值取出直至遇到 nums[j] 或栈空(即 nums[i] 无需删除)。
代码:
1 | class Solution |
时间复杂度:,空间复杂度:,n 为 nums 的长度。
到达角落需要移除障碍物的最小数目
给你一个下标从 0 开始的二维整数数组 grid ,数组大小为 m x n 。每个单元格都是两个值之一:
0表示一个 空 单元格,1表示一个可以移除的 障碍物 。
你可以向上、下、左、右移动,从一个空单元格移动到另一个空单元格。
现在你需要从左上角 (0, 0) 移动到右下角 (m - 1, n - 1) ,返回需要移除的障碍物的 最小 数目。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 1e52 <= m * n <= 1e5grid[i][j]为0或1grid[0][0] == grid[m - 1][n - 1] == 0
示例一:
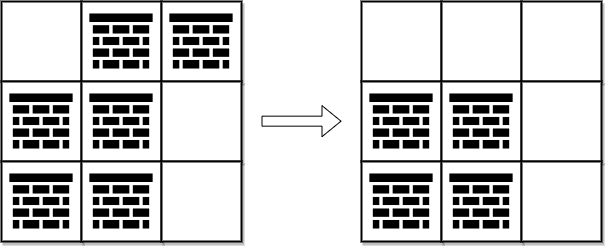
输入:grid = [[0,1,1],[1,1,0],[1,1,0]]
输出:2
解释:可以移除位于 (0, 1) 和 (0, 2) 的障碍物来创建从 (0, 0) 到 (2, 2) 的路径。
可以证明我们至少需要移除两个障碍物,所以返回 2 。
注意,可能存在其他方式来移除 2 个障碍物,创建出可行的路径。
示例二:
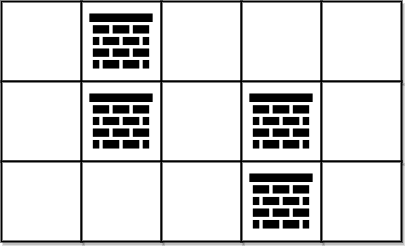
输入:grid = [[0,1,0,0,0],[0,1,0,1,0],[0,0,0,1,0]]
输出:0
解释:不移除任何障碍物就能从 (0, 0) 到 (2, 4) ,所以返回 0 。
解决方案:
单源最短路径问题,空格子表示路径花销为 0,障碍物表示路径花销为 1。
方法一、Dijkstra 算法
Dijkstra 算法是很有名的算法了,不作过多解释,这里使用一个小根堆来维护待计算的点。
代码:
1 | class Solution { |
时间复杂度:,空间复杂度,m,n 分别表示 grid 的行数和列数。
方法二、0-1 BFS
bfs 可以解决所有路径花销为 1 的图的最短理解问题,而 0-1bfs 则可以解决所有路径花销为 0 或 1 的图的最短路径问题。
只要稍微修改 bfs 算法,使得每次计算时优先计算路径花销为 0 的节点,相当于花销为 0 的节点被 “无视掉”,即其前驱节点视为可以 “直接” 连到其后继节点,亦相当于减少花销为 0 的节点的后继结点 bfs 的的层数。
由于只有成功更新距离才会将点入队,但每个点第一次跟新距离后其实就已经计算出最短路径了(因为是层序遍历,虽然可能还有其他的路径可以到达该点,但是距离一定不会小于第一次计算出的距离),所以不需要访问标记 vis,也不会出现环。
代码:
1 | class Solution |
时间复杂度:,空间复杂度,m,n 分别表示 grid 的行数和列数。
 微信
微信 支付宝
支付宝